

3.1 Plus loin à propos du C++
Un manuel ou un ouvrage de référence détaillé du même type est essentiel pour une étude sérieuse du C ou du C++. Allez auprès des maitres : Le langage C de Brian Kernighan et Dennis Ritchie [2] (version originale [1]) est une excellente ressource très maniable pour les fondements de la programmation procédurale tandis que Le langage C++ de Bjarne Stroustrup [6] (version originale [5]) est une référence encyclopédique qui fait autorité.
Le C++ est un langage puissant et complexe dont la syntaxe est semblable à celle du C ou à celle des langages de script de Maple et Mathematica. Un fichier d'entrée d'ePiX est un fichier de code source pour un programme C++ qui écrit un fichier eepic comme fichier de sortie. On peut regarder ePiX comme une extension de C++ ; de la même façon que LATEX fournit une interface de haut niveau à TEX, ePiX fournit un lien de haut niveau entre la puissance de calcul de C++ et l'environnement picture de LATEX.
Comme tout langages de programmation de haut niveau, C++ utilise des variables, des fonctions et des structures de controle. Les variables contiennent des morceaux de données telles que des valeurs numériques, des lieux géométriques, tandis que les fonctions opèrent sur les données. Une structure de controle, comme une boucle ou une instruction conditionnelle, affecte le déroulement du programme en fonction de son état courant. Un fichier source contient essentiellement des « instructions» qui accomplissent des actions allant de la définition d'une variable ou d'une fonction jusqu'à la fixation d'un attribut d'une figure, la réalisation de calculs et l'écriture d'objets sur le fichier de sortie.
Noms et types
Les noms des variables et des fonctions ne doivent contenir que des lettres, des chiffres et le caractère « souligné (_)». Le premier caractère d'un nom ne doit pas être un chiffre et la norme du langage réserve les noms commençant par un souligné aux auteurs de bibliothèques. Les noms sont sensibles à la casse mais c'est en général une mauvaise idée d'utiliser des noms simples avec majuscule et sans majuscule dans un même fichier. On utilise, de manière informelle, de nombreuses conventions pour l'usage des majuscules ; ce document utilise des mots sans majuscule séparés par des soulignés pour les variables et les fonctions et, à l'occasion, utilise des mots en capitales pour les constantes. De même que pour les noms des macros LATEXiennes, la première considération est la clarté (de signification), la lisibilité et la cohérence.
Chaque variable, en C++, a un « type» tel que entier (relatif) (int pour integer), nombre décimal en double précision (double) ou booléen (bool – vrai ou faux –). ePiX fournit des types supplémentaires dont le plus courant est P pour «point». Le constructeur P(x,y,z) crée (le point de coordonnées) (x, y, z) (dans le repère cartésien courant), tandis que P(x,y) donne (x,y,0) c.-à-d. en fait la paire (x,y). Une variable est définie par la donnée (dans l'ordre) de son type, son nom et une expression d'initialisation.
En C et C++, un pointeur est une variable qui contient l'adresse mémoire d'une autre variable. Bien que plus délicats que des variables ordinaires, les pointeurs sont utiles pour écrire certains algorithmes comme ceux de tri.1
Le C++ fournit également des variables références ce qui permet de donner aux variables un pseudonyme. Leur utilisation vient de la manière dont les fonctions C++ traitent leurs arguments, voir page ??.
Fonctions
Dans un langage de programmation, le terme « fonction» fait référence à un bloc de code qu'on peut appeler par son nom. Une fonction C++ prend une liste « d'arguments» et possède une « valeur de retour». Il faut fournir ces informations, ainsi que le nom de la fonction, lorsque l'on définit une fonction. On ne peut pas définir une fonction à l'intérieur d'une autre. Toutefois une fonction peut appeler d'autres fonctions (elle-même aussi2) lors de son exécution :
int factorial(unsigned int n)
{
if (n == 0) return 1;
else return n*factorial(n-1);
}
Le type spécial void représente un « type nul». Une fonction qui accomplit une action mais ne retourne pas de valeur a comme type de retour le type void. Une fonction sans argument peut être vue comme prenant un unique argument de type void.
Tout programme doit avoir une fonction spéciale nommée main() qui est appelée par le système d'exploitation quand on lance le programme. Les arguments de main() sont ceux de la ligne de commande et elle retourne un entier qui signale le succès ou l'échec. Les fonctions de l'utilisateur doivent être définies avant l'appel de main() ou dans un fichier compilé séparément.
Les fonctions en C++ peuvent être aussi simple qu'une formule algébrique ou aussi complexe qu'un algorithme arbitraire. Les algorithmes de calcul de plus grand commun diviseur, de somme finie, de dérivée et intégrale numérique, de tracé de courbes fractales définies récursivement ou de courbe d'ajustement sont quelques unes des applications d'ePiX. Les nombreux fichiers d'exemple contiennent des algorithmes, du niveau de l'utilisateur, qui ne nécessitent pas de connaissance des structures de données internes d'ePiX. Le fichier source functions.cc contient des fonctions simples définies par des algorithmes et functions.h illustre l'utilisation des gabarits (template) de C++. Dans d'autres fichiers sources, tel que plots.cc, on trouvera la règle de Simpson, la méthode d'Euler etc.
Une erreur, comme une division par zéro ou la tentative de prendre l'intersection de deux lignes parallèles, peut apparaitre lorsqu'une fonction est exécutée. Dans cette situation, une fonction C++ peut « lancer une exception» ou retourner un type d'erreur que l'appelant « attrape» et manipule. Si une exeption est lancée mais pas attrapées, le programme s'achève. Les opérateurs d'intersection d'ePiX lancent des exceptions lorsque certaines conditions ne sont pas réunies.
Fonctions mathématiques
C++ connait de plusieurs fonctions mathématiques classiques par leur nom :
sqrt exp log log10 ceil floor fabs
(fabs est la valeur absolue d'un argument décimal.) ePiX fournit des fonctions trigonométriques et leurs inverses sensibles au mode angulaire :
Les inverses des fonctions trigonométriques sont les branches principales.
La fonction pow(x,y) retourne xy lorsque x > 0 et atan2(u,x) (N.B. ordre des arguments) retourne Arg(x+iy)∈(−π,π], la branche principale de arg. C++ connait de nombreuses constantes avec 20 décimales telles que M_PI, M_PI_2 et M_E pour π, π/2, et e respectivement. ePiX ajoute quelques fonctions :
recip sgn zero sinx cb id proj1 proj2
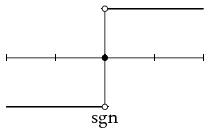
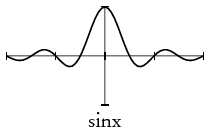
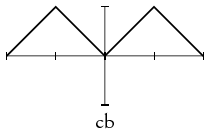
recip est la fonction « inverse de» définie comme valant 0 en 0 ; sgn est la fonction signum ; zero est la fonction constante nulle ; sinx est la fonction définie par x↦ sin(x)/x prolongée par continuité ; cb (pour « Charlie Brown») est le prolongement 2-périodique de la valeur absolue réduite à [−1, 1] ; id est l'identité, définie pour un type arbitraire de données ; les fonctions proj retournent leur premier et seconde variable quel qu'en soit le type.
La bibliothèque GNU C++ définit d'autres fonctions, entre autres les fonctions hyperboliques inverses (acosh , etc.), log et exp en base 2, 10 ou b arbitraire (log2 , etc.), les fonctions d'erreur et gamma (erf et tgamma [sic], respectivement), les fonctions de Bessel de 1et 2espèce : j0 , j1 , y0 , etc. On utilise, par exemple, jn(5, ) pour obtenir les indices supérieurs. Le manuel de référence de la bibliothèque GNU C++ [3] décrit ces fonctions, et d'autres, en détail.
On peut utiliser les fonctions dans des définitions postérieures. Les fonctions de deux variables ou plus sont définies de façon analogue à celle d'une seule variable :
double f(double t) { return t*t*log(t*t); } // t^2 \ln(t^2)
double g(double s, double t) { return exp(2*s)*Sin(t); }
Introduction aux classes
Contrairement au C, le C++ fournit la possibilité d'utiliser la «programmation orientée objet». En deux mots, une classe est la réalisation en code informatique d'un certain concept, tel que le point, la sphère, un graphe que l'on peut tracer ou une caméra. Les classes permettent au programmeur de séparer l'interface d'un objet (l'ensemble des opérations ayant un sens) de son implantation (les structures de données et les algorithmes qui réalisent cette interface).
L'implantation d'une classe comporte des membres (éléments nommés de données) et des fonctions membres (fonctions qui appartiennent à la classe et ont un accès libre à ses membres). Les classes C++ appliquent des permissions d'accès à leurs membres, protégeant ainsi les données de manipulations qui ne passeraient pas par l'interface.
Une interface idéale ressemble à une boite noire : elle cache complètement l'implantation. Afin de collaborer deux classes n'ont besoin que de connaitre leurs interfaces. Cette séparation de la forme et de la fonction rend les programmes modulaires, facilite le débogage, la réutilisation du code et la maintenabilité générale, particulièrement dans les gros programmes.
En programmation simple, on peut traiter les classes comme des types intégrés. Chaque objet d'une classe a ses propres fonctions membres dont la syntaxe d'appel diffère d'un appel de fonction « classique» :
circle C1(P(1,0), 1.5); // cercle de centre et rayon donnés C1.draw(); // fonction membre circle::draw();
Bien entendu, cet appel dessine le cercle C1. De façon générale, un appel de fonction membre est composé du nom d'un objet de la classe, d'un point et du nom de la fonction membre. Les arguments, s'il y en a, sont placés entre parenthèses après le nom de la fonction membre, comme pour un appel de fonction habituelle.
Quelques courts paragraphes ne peuvent qu'au plus effleurer la surface de la programmation orientée objet et de l'utilisation des classes. Consultez à ce propos un ouvrage comme celui de Stroustrup [6] (original [5]) pour plus de détails.
Références et arguments de fonction
Le C et le C++ sont des langages dans lesquels les arguments sont « passés par valeur». Les variables ne sont pas passées à la fonction mais des copies en sont faites et la fonction ne travaille que sur les copies. Bien que cette caractéristique entraine parfois quelques inconvénient, elle empêche les modifications intempestives des variable lors d'un appel de fonction dans une autre partie du programme. Le passage par valeur localise donc la logique d'un programme et protège de bogues faciles à écrire mais extrèmement difficiles à trouver.
Il y a deux raisons habituelles pour permettre à une fonction l'accès à une variable plutôt qu'à une copie : la variable est une grosse structure de données dont la copie a un « cout prohibitif» ; la fonction doit changer la valeur de certains de ses arguments (p. ex. une fonction echange(x,y) qui échange les valeurs de x et de y). Dans chacune de ces situations, une valeur peut être passée par référence. En gros, une référence fournit efficacité d'un pointeur (adresse mémoire) en taille mais peut être crée et manipulée dans un fichier comme une variable ordinaire.
Chaque variable référence est « liée» à un objet existant. Les instructions
double x=1; // définition d'une variable ordinaire double& rx=x; // liaison d'une référence, notez le &
définissent une variable x de valeur 1 puis y lie la variable référence rx. Tant que rx existe, elle fait référence à x. Si la valeur de x change, la valeur de rx fait de même. Toutefois rx a la taille d'un pointeur, quelle que soit la taille de x, ce qui fait qu'on peut passer rx efficacement à un appel de fonction.
De temps à autres, une fonction a un besoin légitime de changer les valeurs de ses arguments. Dans un tel cas, un appel par référence permet une solution propre. Cette technique de mise à jour de variables est présentée comme une fonctionnalité de C++. Toutefois un telle tromperie circonvient à l'encapsulation des données assurée par le passage par valeur et on devrait l'éviter sauf en cas d'absolue nécessité. Si une fonction ne fait que « mettre à jour» la valeur d'une variable, cette variable devrait problablement être de type de classe et sa mise à jour faite par une fonction membre.
Les fonctions qui utilisent des variables références pour des arguments de taille importante peuvent le faire en toute sécurité en déclarant leurs arguments const. Ce mot-clé signifie que la fonciton ne change pas la valeur de l'argument. Toute tentative de modification d'un argument const sera arrêtée par le compilateur.
La déclaration d'une fonction doit indiquer que ses arguments sont des références. Les déclarations ci-dessous ont les significations idiomatiques indiquées.
class matrix; double det(matrix); // passage par valeur, peut-être inefficace matrix& transpose(matrix&); // modifie probablement son argument double trace(const matrix&); // ne modifie pas son argument
Contrairement aux pointeurs, les arguments référence n'impose aucun fardeau syntactique à l'utilisateur. Si A est une matrix (matrice) alors transpose(A); et trace(A); compilent. Vous n'avez pas besoin de déclarer explicitement des variables références pour les passer à la fonction.
Surcharge
C++ fournit la « surcharge» : plusieurs fonctions peuvent avoir le même nom pour autant que le nombre ou le type de leurs arguments soient différents. (Il ne suffit pas que le type de retour soit différent. Le compilateur doit être capable de sélectionner la fonction à partir de sa syntaxe d'appel.) Pour l'utilisateur il semble que la même fonction manipule intelligemment de multiple listes d'arguments. Naturellement, les noms surchargés devraient faire référence à des fonctions conceptuellement apparentées. ePiX, par exemple, fournit de nombreuse fonctions plot.
Portée
Une instructions C++ finit avec un point-virgule. Une collection d'instructions encloses dans une paire d'accolades est un « bloc de code» et peut être vue comme une unique instruction logique. Les accolades déterminent une «portée» à l'intérieur de laquelle on peut réutiliser des noms de variable sans risque d'ambiguïté. Une variable définie entre accolades est dite locale (à la portée dans laquelle elle est définie) ; sa valeur ne peut être utilisée en dehors de la portée.
Le corps d'une fonction est un bloc de code, comme les différentes branches associées à une instruction de controle. Le compilateur n'est pas très regardant à propos des espaces, tabulations et sauts de ligne aussi le fichier source devrait être organisé de telle façon qu'il soit facile à lire. Un renfoncement (indentation) montre un niveau d'imbrication dans les blocs de code mais les détails spécifiques font l'objet de débats passionnés. De même qu'avec le nommage des variables, la clarté et la cohérence sont les critères importants.
Entêtes et précompilateur
Un source C++ est compilé en plusieurs étapes qui se suivent à l'insu de l'utilisateur. La première, le prétraitement (ou précompilation), procède au remplacement simple de texte par inclusion de fichier, développement de macros et de d'instruction conditionnelle de compilation. Ensuite, le source est compilé et assemblé : les instructions écrites en langage lisible par l'homme sont analysées puis traduites en assembleur. Enfin les fichiers objets sont liés : les appels de fonction sont transformées en offsets de fichiers codés en dur, en impliquant éventuellement des fichiers externes de bibliothèque, et les instructions du programme sont empaquetées dans un exécutable binaire que le système d'exploitation peut utiliser.
Le prétraitement est beaucoup moins utilisé en C++ qu'en C ; le langage lui-même permet de remplacer les macros par des fonctionnalités plus sûres et plus riches telles que les variables const et les fonctions en-ligne. L'inclusion de fichier et la compilation conditionnelle donnent les occasions principales d'utiliser un précompilateur. Des lignes de la forme
#include <cstdlib> #include "epix.h"
fait que le contenu du fichier d'entête est lu dans le fichier source. Un fichier d'entête contient des déclarations de variables et de fonctions, des instructions qui spécifient des noms et des types mais ne définissent pas vraiment des données. Les déclarations disent au compilateur juste assez pour qu'il puisse résoudre les appels d'expressions et de fonctions sans connaitre les valeurs spécifiques ou les définitions des fonctions.
La compilation conditionnelle ressemble au code conditionnel de LATEX. Par exemple, un fichier peut produire une sortie couleur ou monochrome comme suit :
#ifdef COLOR ... // code pour créer la figure en couleur #endif // COLOR #ifndef COLOR ... // code monochrome #endif // undef COLOR
Le « symbole de compilation» COLOR est un nom ordinaire de C++. Pour
controler la compilation on peut soit placer une ligne #define COLOR
dans le fichier soit (mieux) fournir le drapeau dans la ligne de commande :
epix -DCOLOR <file.xp>
À chaque #ifdef doit correspondre un #endif. Placer une
commentaire à chaque #endif est une bonne habitude ; dans un fichier
réel, le début et la fin d'un bloc conditionnel peuvent être séparés de plus
d'un écran.
Comparaison avec la syntaxe de LATEX
En tant que langage de programmation, C++ fournit certaines fonctionnalités communes à tous les langages (tels que LATEX, Metapost, Perl, Lisp…) et suit des règles de grammaire. Les différences les plus marquées entre LATEX et C++ sont
- Toute instruction C++ et tout appel de fonction doit être terminé par un point-virgule. L'oubli d'un point-virgule peut entrainer des messages d'erreur cryptique de la part du compilateur. Les directives du précompilateur, qui commencent avec un #, ne sont pas terminées par un point-virgule ;
- La barre oblique inverse est un caractère d'échappement en C++:
// Place l'étiquette $y=\sin x$ en (2,1) // Notez la barre oblique ^ unique dans le fichier de sortie label(P(2,1), P(0,0), "$y=\\sin x$"); // et la double barre ^^ dans le source
- Les noms de variables et de fonctions ne peuvent contenir que des lettres (y compris le souligné) et des chiffres, sont sensibles à la casse et doivent commencer par une lettre ;
- En C++ les variables doivent avoir un type déclaré comme int (entier) ou double (décimal en double précision). Si une variable a une portée globale et que sa valeur n'est pas modifiée, sa définition devrait être placée dans le préambule ou au début de main. Les variables locales devraient être définies dans la plus petite portée possible. Contrairement au C, C++ permet de définir les variables à leur première apparition ;
- C++ exige l'utilisation explicite de * pour noter la multiplication ; la
juxtaposition n'est pas suffisante. C++ ne permet pas l'utilisation de
^pour l'exponentiation, p. ex.t^2est non valide, à la place il faut utiliser t*t ou pow(t,2). - C++ permet des commentaires unilignes ou multilignes. Tout ce qui est situé
entre une double barre oblique // et le saut de ligne est ignoré. Les
chaines
/*et*/délimitent des commentaires multilignes. Un commentaire uniligne peut être inclus dans un commentaire multiligne mais le compilateur n'accepte pas les commentaires multilignes imbriqués.
À eux deux, C et C++ réservent environ 100 mots clés que l'on ne peut pas utiliser comme nom de variable ou de fonction.
- 1
- Au Japon, les adresses des batiments sont attribuées chronologiquement plutôt qu'en référence à l'emplacement dans la rue. Un batiment est analogue à une variable tandis que son adresse est celui d'un pointeur. Si le parlement japonais adoptait une loi rendant obligatoire l'attribution de numéros consécutifs le long des rues, il y aurait deux façons de procéder : déplacer les batiments (bouger les variables) ou renuméroter les batiments sans qu'ils bougent – sur place – (trier les pointeurs). Pour de semblables raisons d'efficacité, les algorithmes de tri en C++ travaillent avec les pointeurs.
- 2
- Note du TdS : On a donc en C++ la possibilité d'implanter des fonctions récursives.